Theresa Eimer
What is Reinforcement Learning?
Supervised Learning requires us to create a dataset and associated labels on which we can train a function approximator, such as a Neural Network. For example, for the task of classifying whether an image is that of a cat or a dog, we would first create a dataset of such images with a label indicating whether each image is a cat or a dog and then use it to train a function approximator.
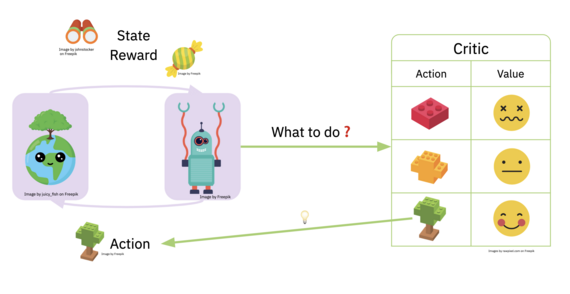
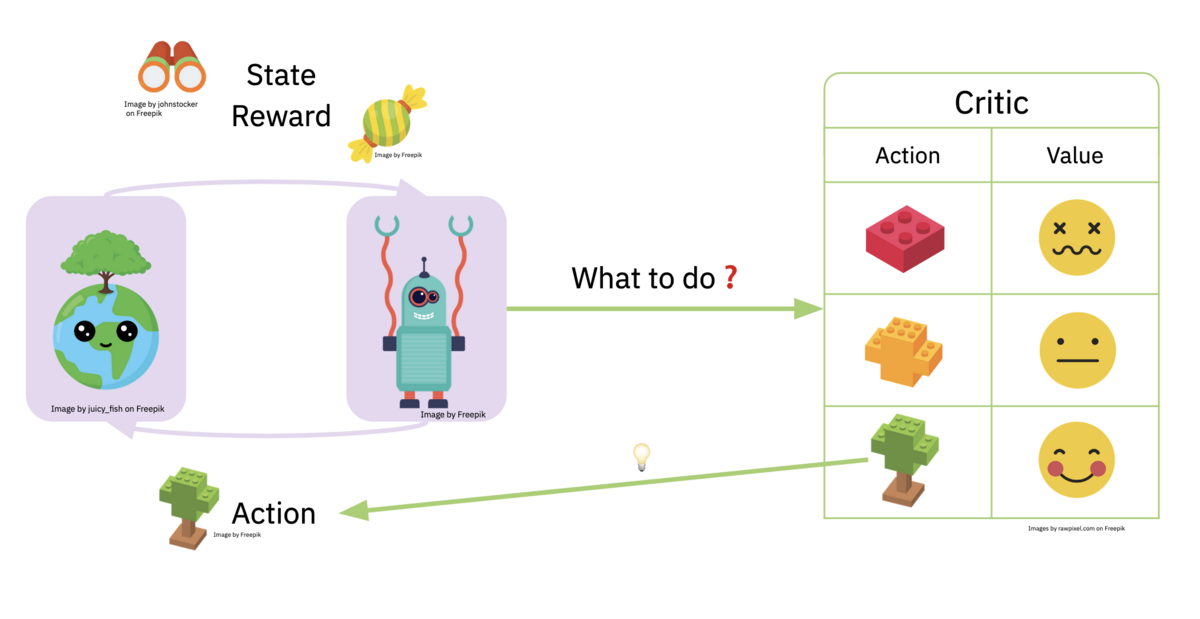
Reinforcement Learning takes a different view. Instead of having a fixed dataset, it looks at the learning problem as an agent interacting with an environment. The agent takes actions in the environment and gets rewarded based on the quality of these actions. The agent needs to learn an optimal way of selecting actions - called a policy - that allows it to maximize the expected reward.

Why do we need AutoRL?
RL agents are capable of solving hard problems like predicting protein structures or controlling the plasma in nuclear fusion reactors. However, they are also brittle to changes in the environment. For example, in the task of balancing a pole on a cart, small changes to the length of the pole can significantly bring down the performance of a previously optimal policy.
Additionally, just like in other areas of Machine Learning, design decisions can have a significant impact on the performance of the agent. The iterative nature of RL, where the agent generates its own training data by interacting with the environment, exacerbates this problem even further.
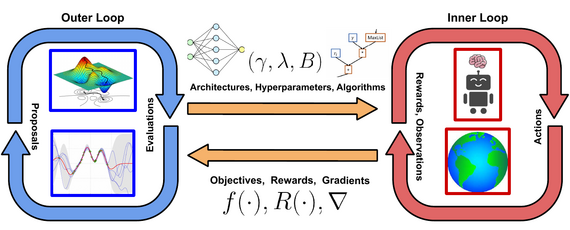
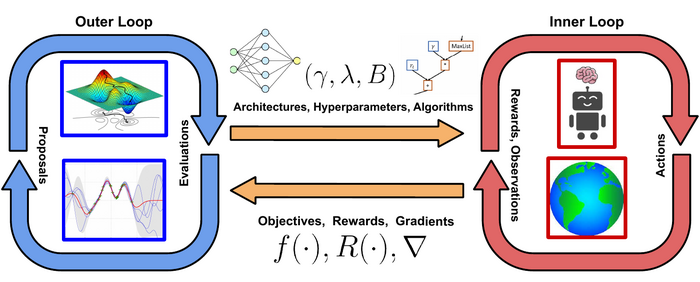
Therefore we need methods to robustify RL agents against changes in their environment and help us make the right design decisions - AutoRL methods.
AutoML ideas for AutoRL
As RL is a highly dynamic optimization process that benefits from online configuration by AutoRL procedures like exploration algorithms or task curricula, our expertise in DAC, Hyperparameter Optimization and Meta-Learning is an ideal starting point for automating RL. We can not only directly apply many of the tools we develop for HPO and DAC to improve the performance of RL agents, we can also use AutoML ideas and best practices to analyze the hyperparameter landscape of RL in order to make training RL agents more interpretable. Furthermore, better analysis of task distributions as well as ways of incoporating task information allows us to construct more general agents. We aim to bring the data-driven philosophy of AutoML to the realm of RL, by developing agents that can configure their own hyperparameters while being robust to noise and sample efficient.